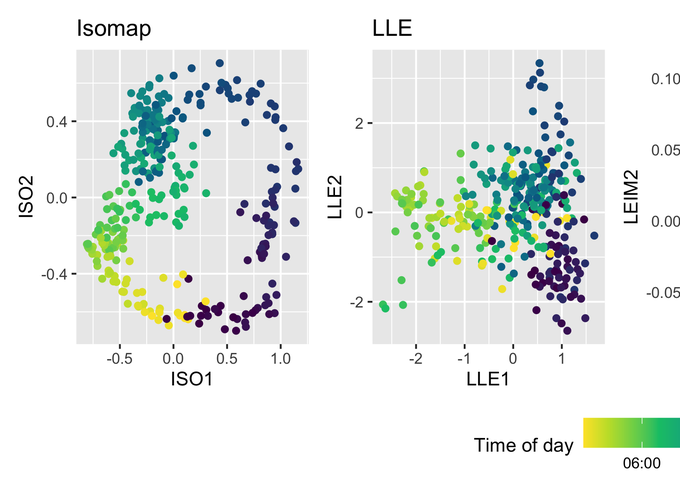
Manifold learning algorithms are valuable tools for the analysis of high-dimensional data, many of which include a step where nearest neighbors of all observations are found. This can present a computational bottleneck when the number of observations is large or when the observations lie in more general metric spaces, such as statistical manifolds, which require all pairwise distances between observations to be computed. We resolve this problem by using a broad range of approximate nearest neighbor algorithms within manifold learning algorithms and evaluating their impact on embedding accuracy. We use approximate nearest neighbors for statistical manifolds by exploiting the connection between Hellinger/Total variation distance for discrete distributions and the L2/L1 norm. Via a thorough empirical investigation based on the benchmark MNIST dataset, it is shown that approximate nearest neighbors lead to substantial improvements in computational time with little to no loss in the accuracy of the embedding produced by a manifold learning algorithm. This result is robust to the use of different manifold learning algorithms, to the use of different approximate nearest neighbor algorithms, and to the use of different measures of embedding accuracy. The proposed method is applied to learning statistical manifolds data on distributions of electricity usage. This application demonstrates how the proposed methods can be used to visualize and identify anomalies and uncover underlying structure within high-dimensional data in a way that is scalable to large datasets.